A
virtual LAN, commonly known as a
VLAN, is a group of hosts with a common set of requirements that communicate as if they were attached to the same
broadcast domain, regardless of their physical location. A VLAN has the same attributes as a physical
LAN, but it allows for end stations to be grouped together even if they are not located on the same
network switch. Network reconfiguration can be done through software instead of physically relocating devices.
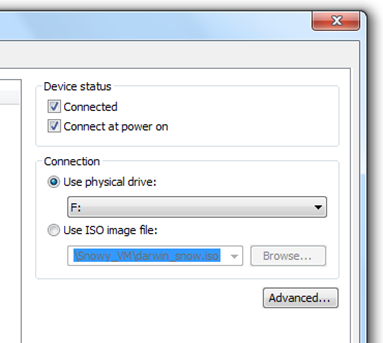
To physically replicate the functions of a VLAN, it would be necessary to install a separate, parallel collection of network cables and switches/hubs which are kept separate from the primary network. However unlike a physically separate network, VLANs must share bandwidth; two separate one-gigabit VLANs using a single one-gigabit interconnection can both suffer reduced throughput and congestion. It visualizes VLAN behaviors (configuring switch ports, tagging frames when entering VLAN, lookup MAC table to switch/flood frames to trunk links, and untagging when exit from VLAN.)
Uses
VLANs are created to provide the segmentation services traditionally provided by routers in LAN configurations. VLANs address issues such as scalability, security, and network management. Routers in VLAN topologies provide broadcast filtering, security, address summarization, and traffic flow management. By definition, switches may not bridge IP traffic between VLANs as it would violate the integrity of the VLAN broadcast domain.
This is also useful if someone wants to create multiple
Layer 3 networks on the same
Layer 2 switch. For example, if a
DHCP server (which will broadcast its presence) is plugged into a switch it will serve any host on that switch that is configured to get its IP from a DHCP server. By using VLANs you can easily split the network up so some hosts won't use that DHCP server and will obtain
link-local addresses, or obtain an address from a different DHCP server.
Virtual LANs are essentially
Layer 2 constructs, compared with IP
subnets which are
Layer 3 constructs. In an environment employing VLANs, a one-to-one relationship often exists between VLANs and IP subnets, although it is possible to have multiple subnets on one VLAN or have one subnet spread across multiple VLANs. Virtual LANs and IP subnets provide independent Layer 2 and Layer 3 constructs that map to one another and this correspondence is useful during the network design process.
By using VLANs, one can control traffic patterns and react quickly to relocations. VLANs provide the flexibility to adapt to changes in network requirements and allow for simplified administration.
History
In 1984,
Dr. W David Sincoskie was attempting to develop Voice over Ethernet for Bellcore. His early estimates figured that a successful network would need roughly a terabit of bandwidth to function. Since at this time routing was slow and complex, the solution was to make an Ethernet-based system which would scale. The problem with a traditional Ethernet-switched network was that it operates as a spanning-tree and suffers from the fact that the roots prove to be bottlenecks. Since the speeds being dealt with would total 1 terabit, and 100Mb ethernet was still theoretical, current ethernet systems could not be used and another solution was needed. Another downside to a traditional Ethernet-based solution was that there was always a single point of failure. Dr. Sincoskie hypothesized that the
bridging algorithm could be applied to spanning trees in order to create smaller segregated networks which would reduce the bandwidth needed at each root in the tree.
[1] In order to allow this to happen, a tree number would need to be inserted into each packet, either implicitly or through the creation of an additional field. This additional field is what is now known in the Ethernet frame as the 802.1Q header, or the VLAN tag. Dr. Sincoskie referred to it as the multitree bridge. With the help of
Dr. Chase Cotton, the two created and refined the algorithms (called the Extended Bridge Algorithms for Large Networks) necessary to make the system feasible and published their results in the 1988 IEEE Network.
[2]
Implementation
A basic switch not configured for VLANs will either have VLAN functionality disabled, or will have it permanently enabled with what is known as a
default VLAN which simply contains all ports on the device as members.
Configuration of the first custom VLAN port group usually involves subtracting ports from the default VLAN, such that the first custom group of VLAN ports is actually the second VLAN on the device, apart from the default VLAN. The default VLAN typically has an ID of 1.
If a VLAN port group were to only exist on the one device, all ports that are members of the VLAN group only need to be "untagged". It is only when the port group is to extend to another device that tagging is used. For communications to occur from switch to switch, an uplink port needs to be a tagged member of every VLAN on the switch that uses that uplink port, including the default VLAN.
Some switches either allow or require a name be created for the VLAN, but it is only the VLAN group number that is important from one switch to the next.
Where a VLAN group is to simply pass through an intermediate switch via two pass-through ports, only the two ports need to be a member of the VLAN, and are tagged to pass both the required VLAN and the default VLAN on the intermediate switch.
Management of the switch requires that the management functions be associated with one of the configured VLANs. If the default VLAN were deleted or renumbered without moving the management to a different VLAN first, it is possible to be locked out of the switch configuration, requiring a forced clearing of the device configuration to regain control.
Switches typically have no built-in method to indicate VLAN port members to someone working in a wiring closet. It is necessary for a technician to either have management access to the device to view its configuration, or for VLAN port assignment charts or diagrams to be kept next to the switches in each wiring closet. These charts must be manually updated by the technical staff whenever port membership changes are made to the VLANs.
Remote configuration of VLANs presents several opportunities for a technician to accidentally cut off communications and lock themselves out of the devices they are attempting to configure. Actions such as subdividing the default VLAN by splitting off the switch uplink ports into a separate new VLAN can suddenly cut off all remote communication, requiring the technician to physically visit the device in the distant location to continue the configuration process.
Motivation
In a legacy network, users were assigned to networks based on geography and were limited by physical topologies and distances. VLANs can logically group networks so that the network location of users is no longer so tightly coupled to their physical location. Technologies able to implement VLANs are:
Protocols and design
The protocol most commonly used today in configuring virtual LANs is
IEEE 802.1Q. The IEEE committee defined this method of multiplexing VLANs in an effort to provide multivendor VLAN support. Prior to the introduction of the 802.1Q standard, several proprietary protocols existed, such as
Cisco's
ISL (Inter-Switch Link) and
3Com's VLT (Virtual LAN Trunk). Cisco also implemented VLANs over
FDDI by carrying VLAN information in an
IEEE 802.10 frame header, contrary to the purpose of the
IEEE 802.10 standard.
Both ISL and IEEE 802.1Q tagging perform "explicit tagging" - the frame itself is tagged with VLAN information. ISL uses an external tagging process that does not modify the existing Ethernet frame, while 802.1Q uses a frame-internal field for tagging, and so does modify the Ethernet frame. This internal tagging is what allows IEEE 802.1Q to work on both access and trunk links: frames are standard Ethernet, and so can be handled by commodity hardware.
The IEEE 802.1Q header contains a 4-byte tag header containing a 2-byte tag protocol identifier (TPID) and a 2-byte tag control information (TCI). The TPID has a fixed value of 0x8100 that indicates that the frame carries the 802.1Q/802.1p tag information. The TCI contains the following elements:
- Three-bit user priority
- One-bit canonical format indicator (CFI)
- Twelve-bit VLAN identifier (VID)-Uniquely identifies the VLAN to which the frame belongs
The 802.1Q standard can create an interesting scenario on the network. Recalling that the maximum size for an Ethernet frame as specified by IEEE 802.3 is 1518 bytes, this means that if a maximum-sized Ethernet frame gets tagged, the frame size will be 1522 bytes, a number that violates the IEEE 802.3 standard. To resolve this issue, the 802.3 committee created a subgroup called 802.3ac to extend the maximum Ethernet size to 1522 bytes. Some network devices that do not support a larger frame size will process the frame successfully but may report these anomalies as a "baby giant."
[3]
Inter-Switch Link (ISL) is a Cisco proprietary protocol used to interconnect multiple switches and maintain VLAN information as traffic travels between switches on trunk links. This technology provides one method for multiplexing bridge groups (VLANs) over a high-speed backbone. It is defined for Fast Ethernet and Gigabit Ethernet, as is IEEE 802.1Q. ISL has been available on Cisco routers since Cisco IOS Software Release 11.1.
With ISL, an Ethernet frame is encapsulated with a header that transports VLAN IDs between switches and routers. ISL does add overhead to the packet as a 26-byte header containing a 10-bit VLAN ID. In addition, a 4-byte CRC is appended to the end of each frame. This CRC is in addition to any frame checking that the Ethernet frame requires. The fields in an ISL header identify the frame as belonging to a particular VLAN.
A VLAN ID is added only if the frame is forwarded out a port configured as a trunk link. If the frame is to be forwarded out a port configured as an access link, the ISL encapsulation is removed.
Early network designers often configured VLANs with the aim of reducing the size of the
collision domain in a large single
Ethernet segment and thus improving performance. When Ethernet
switches made this a non-issue (because each switch port is a collision domain), attention turned to reducing the size of the
broadcast domain at the
MAC layer. Virtual networks can also serve to restrict access to network resources without regard to physical topology of the network, although the strength of this method remains debatable as
VLAN Hopping [4] is a common means of bypassing such security measures.
Virtual LANs operate at Layer 2 (the
data link layer) of the
OSI model. Administrators often configure a VLAN to map directly to an IP network, or
subnet, which gives the appearance of involving Layer 3 (the
network layer). In the context of VLANs, the term "trunk" denotes a network link carrying multiple VLANs, which are identified by labels (or "tags") inserted into their packets. Such trunks must run between "tagged ports" of VLAN-aware devices, so they are often switch-to-switch or switch-to-
router links rather than links to hosts. (Note that the term 'trunk' is also used for what Cisco calls "channels" :
Link Aggregation or Port Trunking). A
router (Layer 3 device) serves as the
backbone for network traffic going across different VLANs.
Cisco VLAN Trunking Protocol (VTP)
On
Cisco Devices, VTP (VLAN Trunking Protocol) maintains VLAN configuration consistency across the entire network. VTP uses Layer 2 trunk frames to manage the addition, deletion, and renaming of VLANs on a network-wide basis from a centralized switch in the VTP server mode. VTP is responsible for synchronizing VLAN information within a VTP domain and reduces the need to configure the same VLAN information on each switch.
VTP minimizes the possible configuration inconsistencies that arise when changes are made. These inconsistencies can result in security violations, because VLANs can cross connect when duplicate names are used. They also could become internally disconnected when they are mapped from one LAN type to another, for example, Ethernet to ATM LANE ELANs or FDDI 802.10 VLANs. VTP provides a mapping scheme that enables seamless trunking within a network employing mixed-media technologies.
VTP provides the following benefits:
- VLAN configuration consistency across the network
- Mapping scheme that allows a VLAN to be trunked over mixed media
- Accurate tracking and monitoring of VLANs
- Dynamic reporting of added VLANs across the network
- Plug-and-play configuration when adding new VLANs
As beneficial as VTP can be, it does have disadvantages that are normally related to the
spanning tree protocol (STP) as a bridging loop propagating throughout the network can occur. Cisco switches run an instance of STP for each VLAN, and since VTP propagates VLANs across the campus LAN, VTP effectively creates more opportunities for a bridging loop to occur.
Before creating VLANs on the switch that will be propagated via VTP, a VTP domain must first be set up. A VTP domain for a network is a set of all contiguously trunked switches with the same VTP domain name. All switches in the same management domain share their VLAN information with each other, and a switch can participate in only one VTP management domain. Switches in different domains do not share VTP information.
Using VTP, each Catalyst Family Switch advertises the following on its trunk ports:
- Management domain
- Configuration revision number
- Known VLANs and their specific parameters
Establishing VLAN memberships
The two common approaches to assigning VLAN membership are as follows:
- Static VLANs
- Dynamic VLANs
Static VLANs are also referred to as port-based VLANs. Static VLAN assignments are created by assigning ports to a VLAN. As a device enters the network, the device automatically assumes the VLAN of the port. If the user changes ports and needs access to the same VLAN, the network administrator must manually make a port-to-VLAN assignment for the new connection.
Dynamic VLANs are created through the use of software. With a
VLAN Management Policy Server (VMPS), an administrator can assign switch ports to VLANs dynamically based on information such as the source MAC address of the device connected to the port or the username used to log onto that device. As a device enters the network, the device queries a database for VLAN membership. See also
FreeNAC which implements a VMPS server.
Protocol Based VLANs
In a protocol based VLAN enabled switch, traffic is forwarded through ports based on protocol. Essentially, the user tries to segregate or forward a particular protocol traffic from a port using the protocol based VLANs; traffic from any other protocol is not forwarded on the port. For example, if you have connected a host, pumping ARP traffic on the switch at port 10, connected a Lan pumping IPX traffic to the port 20 of the switch and connected a router pumping IP traffic on port 30, then if you define a protocol based VLAN supporting IP and including all the three ports 10, 20 and 30 then IP packets can be forwarded to the ports 10 and 20 also, but ARP traffic will not get forwarded to the ports 20 and 30, similarly IPX traffic will not get forwarded to ports 10 and 30.
VLAN Cross Connect
VLAN Cross Connect (CC) is a mechanism used to create Switched VLANs, VLAN CC uses IEEE 802.1ad frames where the S Tag is used as a Label as in
MPLS . IEEE does not recommend this model as it violated the basic bridging principles.
Reference :
Virtual_LAN
 Note: We don’t in anyway encourage downloading Apple software via file-sharing / torrent sites and run it in an virtualized environment under Windows. This guide is for informational purposes only. If you like OS X Snow Leopard, Get a Mac.
Note: We don’t in anyway encourage downloading Apple software via file-sharing / torrent sites and run it in an virtualized environment under Windows. This guide is for informational purposes only. If you like OS X Snow Leopard, Get a Mac. Step 4: Click on”Edit virtual machine settings”, select CD/DVD (IDE) option from left hand side and then and select “Use ISO image file” option. Point it to “darwin_snow.iso” which you downloaded in Step 2.
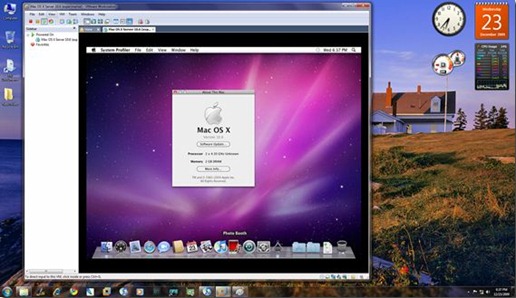
Step 4: Click on”Edit virtual machine settings”, select CD/DVD (IDE) option from left hand side and then and select “Use ISO image file” option. Point it to “darwin_snow.iso” which you downloaded in Step 2.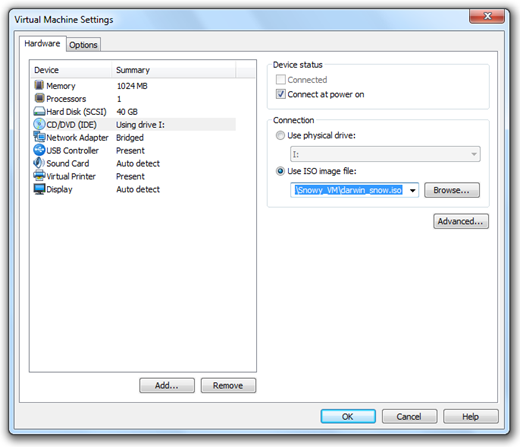 Step 5: Now power on the virtual machine and hit “F8” key. You should now have a screen similar to the one shown below.
Step 5: Now power on the virtual machine and hit “F8” key. You should now have a screen similar to the one shown below.